
آنچه مدیران باید درباره مدلها و مجموعه دادههای هوش مصنوعی بپرسند
راجر دبلیو. هورل و توماس سی. ردمن، ۱۹ دسامبر ۲۰۲۳
قدرت هوش مصنوعی و مدلهای یادگیری ماشینی که بر اساس آن بنا شدهاند، همچنان در حال تغییر قوانین کسبوکار هستند. با این حال، بسیاری از پروژههای هوش مصنوعی – اغلب پس از استقرار، که پرهزینه و ناامید کننده هستند – شکست میخورند. فقط از آمازون در مورد شکستهای تشخیص چهرهاش یا از مایکروسافت در مورد اشتباهاتش با چتبات Tay بپرسید. اغلب اوقات، دانشمندان داده چنین شکستهایی را به عنوان ناهنجاریهای موردی نادیده میگیرند، بدون اینکه به دنبال الگوهایی باشند که میتوانند به جلوگیری از شکستهای آینده کمک کنند. مدیران ارشد کسبوکار امروزی قدرت و مسئولیت جلوگیری از شکستهای استقرار را دارند. اما برای انجام این کار، آنها باید اطلاعات بیشتری در مورد مجموعه دادهها و مدلهای داده، داشته باشند تا هم سؤالات درستی از توسعهدهندگان مدل هوش مصنوعی بپرسند و هم پاسخها را ارزیابی کنند. شاید با خود فکر کنید، «مگر دانشمندان داده آموزشهای سطح بالایی ندیدهاند؟» بخش عمدهای از آموزشهای دانشمندان داده امروزی بر روی مکانیک یادگیری ماشین متمرکز است، نه محدودیتهای آن. این امر باعث میشود دانشمندان داده به ابزار جلوگیری یا تشخیص صحیح شکستهای مدل هوش مصنوعی، مجهز نباشند. توسعهدهندگان هوش مصنوعی باید توانایی یک مدل را برای کار در آینده و فراتر از محدودیتهای مجموعه دادههای آموزشی آن بسنجند، مفهومی که آنها تعمیمپذیری مینامند. امروزه این مفهوم به خوبی تعریف نشده و فاقد دقت کافی است.
یک ضربالمثل در علم تجزیه و تحلیل ادعا میکند که توسعهدهندگان مدل و هنرمندان عادت بد یکسانی دارند و عاشق مدلهای خود میشوند. از سوی دیگر، برای دادهها دقت و توجه لازم صرف نمیشود. به عنوان مثال، برای توسعهدهندگان مدل هوش مصنوعی، بسیار آسان است که به مجموعه دادههای در دسترس بسنده کنند، به جای اینکه به دنبال دادههایی باشند که برای مشکل موجود مناسبتر باشند.
مدیران ارشد کسبوکار، که فاقد مدارک پیشرفته در رشتههای فنی هستند، حتی کمتر برای تشخیص مشکلات مربوط به مدلهای هوش مصنوعی و مجموعه دادهها مجهز هستند. با این حال، این رهبران کسبوکار هستند که در نهایت تصمیم میگیرند که آیا و چگونه مدلهای هوش مصنوعی را به طور وسیع، به کار گیرند. هدف ما در این مقاله کمک به مدیران برای انجام بهتر این کار با استفاده از موارد زیر است:
- چارچوبی که زمینه مورد نیاز را ارائه میدهد. به طور خاص، مفهوم «دادههای مناسب» را معرفی خواهیم کرد. عدم تطابق بین دادههای مناسب و دادههایی که واقعاً در یک پروژه هوش مصنوعی به کار گرفته میشوند، میتواند خطرناک باشد.
- مجموعهای از شش سؤال برای پرسیدن از توسعهدهندگان مدل هوش مصنوعی سازمان، قبل و در حین کار مدلسازی و استقرار
- راهنمایی در مورد چگونگی ارزیابی پاسخهای توسعهدهندگان مدل هوش مصنوعی به این شش سؤال
چگونه دادههای مناسب را شناسایی کنیم: یک چارچوب
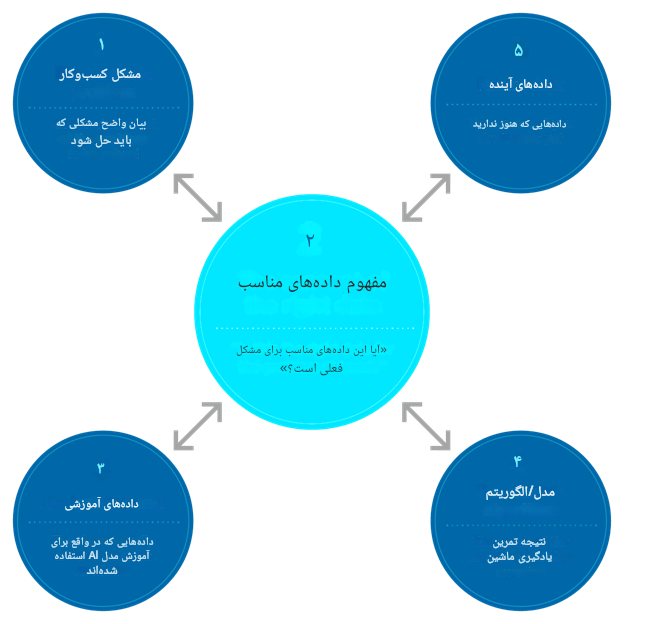
موفقیت یا شکست هر پروژه هوش مصنوعی به مجموعه دادههایی که استفاده میکند بستگی دارد. برای کمک به تیمها در دستیابی به دادههای مناسب، یک چارچوب پنج عنصری را که در زیر نشان داده شده است، ارائه میدهیم. بیایید آن را به اجزای آن تقسیم کنیم.
شکل (۱)
چارچوب دادههای مناسب
آیا آن پروژه هوش مصنوعی محکوم به موفقیت است؟ این چارچوب به شما کمک میکند تا بحثهای آگاهانهتری با توسعهدهندگان مدل هوش مصنوعی داشته باشید. پس از تأیید مشکل تجاری که باید حل شود، شناسایی دادههای مناسب، همانطور که در اینجا نشان داده شده است، مرکز توجه است. بدون مجموعه دادههای مناسب، پروژه هوش مصنوعی شما شکست خواهد خورد. اما شما همچنین باید بخشهای مرتبط را ارزیابی کنید: دادههای آموزشی، مدل هوش مصنوعی و دادههایی که در آینده برای مدل اعمال خواهند شد.
- مشکل و جمعیت مورد نظر. هر علم داده خوب نیاز به بیان واضحی از مشکلی دارد که باید حل شود. هرچند که این موضوع ممکن است بدیهی به نظر برسد، اما متوجه میشویم که توسعهدهندگان مدل هوش مصنوعی اغلب به اندازه کافی به این موضوع فکر نکردهاند یا اعضای تیم درک متفاوتی از مشکل، دارند. به عنوان مثال، هدف نهایی کسب و کار ما در رابطه با یک مدل جدید امتیازدهی خودکار اعتبار چیست؟ آیا صرفهجویی در زمان است؟ آیا جایگزینی بیمهگران است یا صرفاً مشاوره دادن به آنها؟ آیا هدف کاهش خطاهای وامدهی یا کاهش سوگیری است؟ پاسخ ممکن است ترکیبی از این اهداف باشد. یک نکته دیگر: آیا منطق باید برای افرادی که اعتبارشان رد شده است، قابل توضیح باشد یا مدلهای جعبه سیاه هوش مصنوعی، قابل اتکاست؟ پاسخ به این سؤالات مربوط به مشکلات کسب و کار منجر به راهحلهای مختلفی خواهد شد.
- مفهوم دادههای مناسب. اینکه آیا مجموعهای از دادهها برای یک تصمیم، عملیات یا تحلیل خاص مناسب یا مناسب هستند سهم کلیدی در اصول کیفیت دادهها داشته است. بسته به مشکل، جنبههای مختلف و متنوعی از «مناسب بودن برای استفاده» میتواند وجود داشته باشد، اما پرسشهای«آیا دادهها درست هستند؟» و «آیا این دادههای مناسب هستند؟» همیشه مهم هستند.
در اینجا، ما بر این سوال تمرکز خواهیم کرد که «آیا این دادههای مناسب هستند؟» زیرا برای ارزیابی تعمیمپذیری و جلوگیری از شکست پروژه بسیار اهمیت دارند.
برای پاسخ به این سوال، مدیران باید بر شش معیار (که گاهی اوقات ابعاد، ویژگیها، خواص، الزامات یا جنبهها نیز نامیده میشوند) تمرکز کنند:
- مرتبط بودن/کامل بودن: دادهها باید قدرت پیشبینی داشته باشند. در مثال امتیازدهی اعتباری ما، ویژگیهایی مانند سن، سابقه پرداخت دیرهنگام و درآمد ممکن است نقش داشته باشند. در حالت ایدهآل، همه این ویژگیها گنجانده میشوند (که آنچه مدیران باید درباره مدلها و مجموعه دادههای هوش مصنوعی بپرسند.
- جامعیت/نمایندگی کافی: دو مسئله اصلی عبارتند از: «آیا دادهها به طور کافی جمعیت مورد نظر را پوشش میدهند؟» و «آیا به اندازه کافی از آنها برای آموزش مناسب مدل وجود دارد؟» نکته مهم این است که نگرانیهای مربوط به حریم خصوصی یا سایر موارد ممکن است ایجاب کند که برخی از دادهها حذف شوند.
- عدم وجود سوگیری: انواع زیادی از سوگیریها میتوانند در دادهها پنهان باشند و این بُعد مستلزم حذف آنها است. این یک نگرانی ویژه در مثال امتیازدهی اعتباری ما و هر زمان که مسئله مورد نظر مربوط به انسانها باشد، است.
- به موقع بودن: مسئله اساسی این است که «دادهها چقدر باید جدید باشند؟» برای برخی از مشکلات، دادههای قدیمیتر ممکن است حاوی سوگیریهایی باشند که حذف آنها دشوار است. و در برخی از کاربردها، دادههای (آینده) تنها چند ثانیه پس از ایجاد، دیگر مرتبط نیستند.
- تعریف واضح: همه اصطلاحات، از جمله واحدهای اندازهگیری، باید به وضوح تعریف شوند.
- موارد استثنای مناسب: در بحثهای مربوط به مرتبط بودن و جامعیت در بالا، اشاره کردیم که برخی از دادهها باید با توجه به ملاحظات قانونی، نظارتی، اخلاقی و مالکیت معنوی حذف شوند. برای مثال، استفاده از کدهای پستی میتواند جایگزینی برای نژاد در تصمیمات اعتباری باشد و سازمانها باید از نقض قوانینی که نحوه استفاده از اطلاعات شخصی قابل شناسایی را تصریح میکنند، خودداری کنند. نگرانی فزایندهای وجود دارد که مدلهای هوش مصنوعی آموزشدیده بر اساس منابع عمومی ممکن است حقوق مالکیت معنوی را نقض کنند. مدیران یا تیمهای حقوقی شرکتهایشان باید الزامات را تا حد امکان به طور کامل بیان کنند.
- دادههای آموزشی. این به دادههایی اشاره دارد که واقعاً برای آموزش مدل استفاده میشوند، صرف نظر از اینکه آیا در واقع دادههای مناسب هستند یا جایگزینهای آسانتری برای آنها وجود دارد.
- مدل/الگوریتم. این نتیجه تمرین یادگیری ماشین است. پس از آموزش، مدل میتواند در آینده با استفاده از دادههای جدید بهروزرسانی شود که معمولاً به عنوان “دادههای آینده” شناخته میشود.
- دادههای آینده. این به دادههایی اشاره دارد که هنوز ندارید اما در آینده برای مدل هوش مصنوعی اعمال خواهید شد.
توجه داشتن به دادههای مناسب، دادههای آموزشی و دادههای آینده بهترین دفاع در برابر شکستهای شرمآور پروژههای هوش مصنوعی است.
همانطور که در شکل نشان داده شده است، مفهوم دادههای مناسب برای همه چیز وجه بنیادی دارد. ما آن را مفهوم دادههای مناسب مینامیم زیرا بیشتر مربوط به معیارهایی است که امیدوارید دادهها برآورده کنند. توسعهدهندگان مدل ابتدا باید مشکل و جمعیت مورد نظر را روشن کنند. در مرحله بعد، آنها باید معیارهایی را که دادههای مورد استفاده برای آموزش مدل(جهت حل مشکل) داشته باشند را، تعریف کنند. سوم، آنها باید دادههای آموزشی که میتوانند گردآوری کنند را با این معیارها مقایسه کنند. سپس باید مقایسههای مشابهی با دادههای قابل پیش بینی در آینده انجام دهند. شکافها یا عدم تطابقهای بزرگ، نشاندهنده وجود مشکل است.
همانطور که قبلاً اشاره کردیم، توسعهدهندگان به راحتی شیفته مدلهایی میشوند که ساختهاند، و دادههایی که به راحتی به دست میآیند و دادههایی که برای مشکل کسبوکار مناسبتر هستند، ممکن است کاملاً متفاوت باشند. برای جلوگیری از مشکل، رهبران کسبوکار باید تیم را از طریق بررسی دقیق و هوشیارانه دادههای مناسب، دادههای آموزشی و دادههای آینده راهنمایی کنند. این بهترین دفاع در برابر اشتیاق بیش از حد، غرور آشکار مدل و شکستهای شرمآور پروژههای هوش مصنوعی است.
شش سوال نافذ بپرسید
با این توضیحات، توصیه میکنیم مدیران بر اساس چارچوب دادههای مناسب، در سه مرحله کلیدی، مجموعهای از سوالات هدفمند را بپرسند. پرسشگری باید از زمانی که شما مشکل را تعریف میکنید شروع شود و تا زمان استقرار ادامه یابد. ضمناً، اگر در مورد واژگان فنی علم داده به کمک نیاز دارید، به دنبال کسی باشید که بتواند در جلسات با توسعهدهندگان مدل، مباحث را توضیح دهند. برخی شرکتها حتی در حال ایجاد نقشها و گروههای خاصی هستند تا این شکاف بین تیمهای علوم داده و رهبران کسبوکار را پر کنند.
سوالاتی که باید در طول تعریف مسئله بپرسید
توسعهدهندگان باید با پرسیدن دو سوال زیر شروع کنند
- با فرض موفقیتآمیز بودن این پروژه، پیشبینی میکنید مدلهایی که توسعه میدهید چگونه و کجا مورد استفاده قرار خواهند گرفت؟
در پاسخها به دنبال چه چیزی باشید: این سوال برای تعیین درک توسعهدهندگان مدل از مشکل واقعی که کسبوکار سعی در حل آن دارد، در نظر گرفته شده است؛ چه چیزی در محدوده و چه چیزی خارج از محدوده، با توجه به جمعیت مورد نظر؛ و اینکه توسعهدهندگان قصد دارند مدل را تا چه مدت در آینده اعمال کنند.
علاوه بر این، این سوال زمینه را برای دو سوال بعدی فراهم میکند. ما به مدیران توصیه میکنیم که در مورد این سوال بسیار سختگیر باشند. بسیاری از تلاشهای علم داده با عدم موفقیت در بیان مسئله، از همان ابتدا خود را محکوم به فنا میکنند.
- چگونه دادههای آموزشی را که معیارهای دادهای مناسب را برآورده میکنند، به دست خواهید آورد؟
در پاسخها به دنبال چه چیزی باشید: این سوال ممکن است حیاتیترین پرسش باشد. در این مرحله، توسعهدهندگان مدل پیشبینی میکنند که چه دادههایی را میتوانند به دست آورند. مطمئن شوید که توسعهدهندگان معیارهای دادهای مناسب را مرتب کردهاند (با استفاده از شش ملاحظه ذکر شده قبل). در مرحله بعد، بررسی کنید که آیا توسعهدهندگان برنامه معتبری برای به دست آوردن دادههایی که با آن معیارها مطابقت دارند، دارند یا خیر. اگر پاسخهای آنها در این مرحله کافی نبود، آنها را به مرحله طراحی برگردانید.
سوالاتی که باید در طول توسعه مدل هوش مصنوعی بپرسید
پس از اینکه توسعهدهندگان مرحله تعریف مسئله را تکمیل کردند، زمان ساخت مدل هوش مصنوعی فرا میرسد. روی سوالات زیر تمرکز کنید:
- چه گامهایی برای درک تاریخچه کامل، ظرافتها، مزایا و محدودیتهای دادههای آموزشی، برداشتهاید؟ و چگونه آنها با معیارهای داده مناسب، مقایسه میشوند؟
در پاسخها به دنبال “چه چیزی” باشید: در اینجا، میخواهید تأیید کنید که توسعهدهندگان مدل واقعاً دادههایی را که پیشبینی میکردند در سوال ۲ به دست آورند، به دست آوردهاند. آنها را تحت فشار قرار دهید تا معیار به معیار کار کنند، شکافهای موجود در دادههای آموزشی را در مقایسه با دادههای مناسب فهرست کنند، شدت شکافها را ارزیابی کنند و برنامههای خود را برای رفع شکافهای مهم توضیح دهند.
نکته مهم این است که خارج از کتابهای درسی، چیزی به عنوان مجموعه دادههای کامل وجود ندارد، بنابراین انتظار شکافها را داشته باشید. اگر توسعهدهندگان مدل گزارش میدهند که هیچ شکافی وجود ندارد، بسیار مشکوک باشید.
- چگونه بررسی خواهید کرد که دادههای آینده معیارهای داده مناسب را برآورده میکنند؟
در پاسخها به دنبال چه چیزی باشیم: در این زمان، وقتی که توسعهدهندگان مدل تازه کار با دادههای آموزشی را تمام کردهاند، از آنها بخواهید که این موضوع را با دقت بررسی کنند. اگر اینطور نیست، از آنها بخواهید که این موضوع را با دقت بررسی کنند. (سوال ۵ در ادامه این موضوع است.)
توجه داشته باشید که اعتبارسنجی یک مدل با «نگه داشتن» برخی از دادههای آموزشی، راهحل قابل قبولی نیست. در Kaggle.com و سایر پلتفرمهای رقابت علوم داده، فرض بر این است که دادههای آموزشی از کیفیت قابل قبول و حتی بکری برخوردارند. توسعهدهندگان مدل برای ساختن بهترین پیشبینی بر اساس مجموعهای از دادههای «نگهدار» که از همان مجموعه دادههای اصلی دادههای آموزشی گرفته شده است، رقابت میکنند. بنابراین، از همه جهات مهم، دادههای نگهدارنده دقیقاً شبیه دادههای آموزشی به نظر میرسند. در موقعیتهای واقعی، این اتفاقی نیست که میافتد. به عنوان مثال، در سیستم تشخیص چهره آمازون، دادههای آموزشی از منطقه جغرافیایی محلی آمده بودند، در حالی که قرار بود الگوریتم به طور گستردهتری اعمال شود. این امر به گفته خود آمازون منجر به «کالیبراسیون ضعیف الگوریتم» شد. سوالاتی که باید قبل و در حین استقرار بپرسید
چرا این سوالات را قبل و در حین استقرار بپرسید؟ شما باید چندین بار از آنها بپرسید زیرا تیم در حین استقرار چیزهای جدیدی یاد خواهد گرفت.
- چگونه اطمینان حاصل خواهید کرد که دادههای آینده انتظارات شما را برآورده میکنند؟ چه کنترلهایی برای دادهها و مدلها وجود دارد تا هم استقرار موفقیتآمیز و هم دقت مدل با دادههای آینده تضمین شود؟
در پاسخها به دنبال چه چیزی باشید: این پرسش بر اساس بحث سوال ۴ در مورد دادههای آینده است. در اینجا، شما اطمینان حاصل میکنید که توسعهدهندگان، سیستمی برای ارزیابی دادههای آینده، قبل از استفاده توسط مدل یا استفاده برای طی بهروزرسانی مدل دارند.
این موضوع مهم است زیرا در حالی که شرکتها به بهترین حالت با استقرار مدل هوش مصنوعی امیدوارند، به آنها توصیه میشود که برای بدترین حالت آماده شوند. مدیران باید اطمینان حاصل کنند که توسعهدهندگان مدل یک برنامه کنترلی دارند که از تغییرات در دادههای آینده یا عملکرد ضعیف مدل جلوگیری میکند یا حداقل هشدار اولیه میدهد. به عنوان مثال، چگونه کاهش تدریجی دقت مدل در طول زمان تشخیص داده میشود؟
در حالی که شرکتها به بهترین حالت با استقرار مدل هوش مصنوعی امیدوارند، به آنها توصیه میشود که برای بدترین حالت آماده شوند. در نهایت، برنامههای توسعهدهندگان را برای بهروزرسانی مدلهایشان با در دسترس قرار گرفتن دادههای آینده بررسی کنید.
- سه راه اصلی که ممکن است مدلهای شما در پیادهسازی شکست بخورند چیست؟ چه اقداماتی برای کاهش آنها انجام دادهاید؟
در پاسخها به دنبال چه چیزی باشید: مهندسان مدتها پیش فهمیدند که سیستمهای فنی اغلب با وجود تمام تلاشهایشان شکست میخورند. بنابراین، آنها تجزیه و تحلیل حالت و اثرات شکست یا FMEA را توسعه دادند تا به پیشبینی شکستهای احتمالی قبل از وقوع کمک کنند و برنامههای احتمالی را برای جلوگیری یا حداقل تشخیص آنها اجرا کنند.
متأسفانه، بسیاری از دانشمندان داده هنوز این روش را نپذیرفتهاند. اصرار کنید که توسعهدهندگان مدل کار معادل را انجام دهند. آنها را مجبور کنید تا به طور گسترده در مورد طیف وسیعی از شکستهای احتمالی مربوط به فناوری، افراد، کیفیت دادهها، تغییرات در محیط و سایر مسائل فکر کنند.
گفتگوهای سخت اما حیاتی
ما به خوبی میدانیم که بسیاری از دانشمندان داده و توسعهدهندگان مدل هوش مصنوعی دوست ندارند به این سؤالات پاسخ دهند. اما با توجه به نرخ بالای شکست پروژههای علم داده، پرسیدن «چگونه از شکست پروژههای خود جلوگیری خواهید کرد؟» صرفاً مدیریت خوب است.
علاوه بر این، همانطور که یکی از تیمهای تحقیقاتی گوگل اشاره کرد، «همه میخواهند کار مدلسازی را انجام دهند، نه کار دادهها». رهبران کسبوکار این نعمت را ندارند. تأکید بر دادههای صحیح، نه تنها برای ساخت مدلها، بلکه برای اعتبارسنجی و استفاده از آنها در آینده، شاید مهمترین کاری باشد که مدیران میتوانند برای افزایش میزان موفقیت پروژههای یادگیری ماشینی و هوش مصنوعی انجام دهند.
درباره نویسندگان
راجر دبلیو. هورل، استاد آمار بریت-پشل در کالج یونیون در اسکنکتادی، نیویورک، و نویسنده همکار رونالد دی. اسنی در کتاب «رهبری بهبود جامع با Lean Six Sigma 2.0، ویرایش دوم» (Pearson FT Press، ۲۰۱۸) است. توماس سی. ردمن
رئیس راهکارهای کیفیت داده و نویسندهی کتاب «مردم و داده: اتحاد برای تغییر سازمان شما» (KoganPage، ۲۰۲۳).